

Database and data management technology are going through a Cambrian explosion of different options and flavors. It is a result of a massive amount of development coming from open source, web, and other places. Back in 2013, I wrote a blog discussing PLM data management in the 21st century. Check it out here. Back 20 years ago, the decision diagram about data management technologies looked like this one.
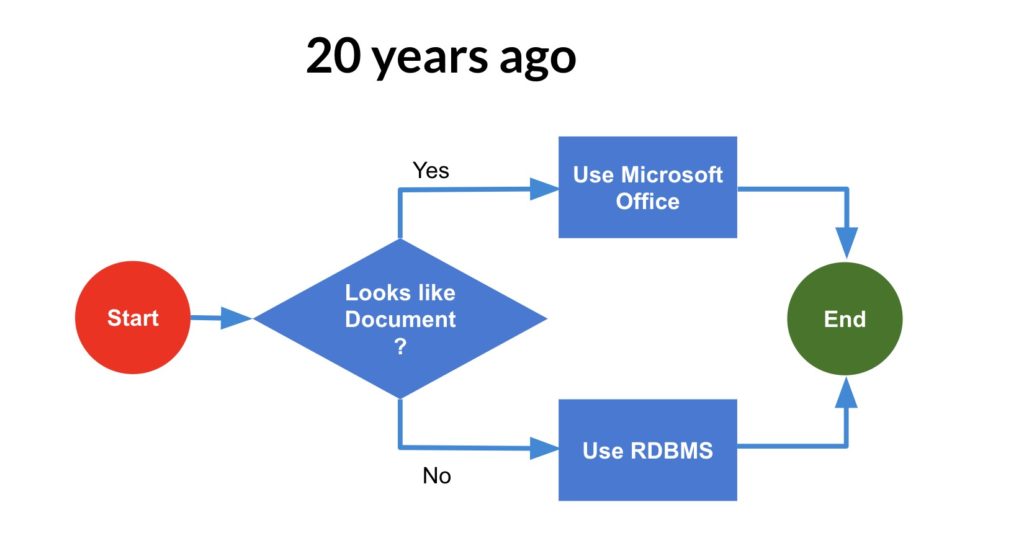
The decision about what RDBMS to use is also interesting. It was mostly driven by IT approval. All PDM/PLM systems required local installation and corporate IT approvals. So, the heavy presence of Oracle and later MS SQL was explained by this factor (unless you sell it via IBM and then DB2 was for some time platform demanded by IBM).
One of my observations back in 2013 was that the database is moving from “solution” into “toolbox” status. A single relational database is no longer a straightforward decision for all your development tasks. A combination of factors created this change:
- Open-source databases (including RDBMS) provided a viable solution with the low cost
- Cloud / SaaS / Web architectures eliminated the need to deploy databases to organization
- No SQL databases provided an interesting alternative for specific data management problems
If you’re not familiar with “No SQL” terms, don’t worry. The scope of NO SQL changed for the last few years, but it literally means everything except relational (aka SQL) databases. No SQL included many flavors – key/value stores, document, columnar, triple stores, and also graph databases. The idea of No SQL is to create a specific database architecture that allows users to store and file data faster than they can with traditional relational databases, which use Structured Query Language (SQL) as the data querying language.
Another interesting trend is the development of polyglot persistence. It feels like a fancy term, but it is actually very simple. Unless you lived under the rock for the last decade, you know that all software applications these days developed using different programming languages. And, it is very common to use multiple programming languages (for example for web user interface and for application servers). So, called polyglot programming was first enabled by dynamic libraries, later SOAP, web services, and recently microservice architecture. The whole point is that you can use the best language. The same with the databases – you can use multiple databases depends on your need. It became an extremely popular decision with microservice architecture in which each service has independent storage and capacity to scale independently.
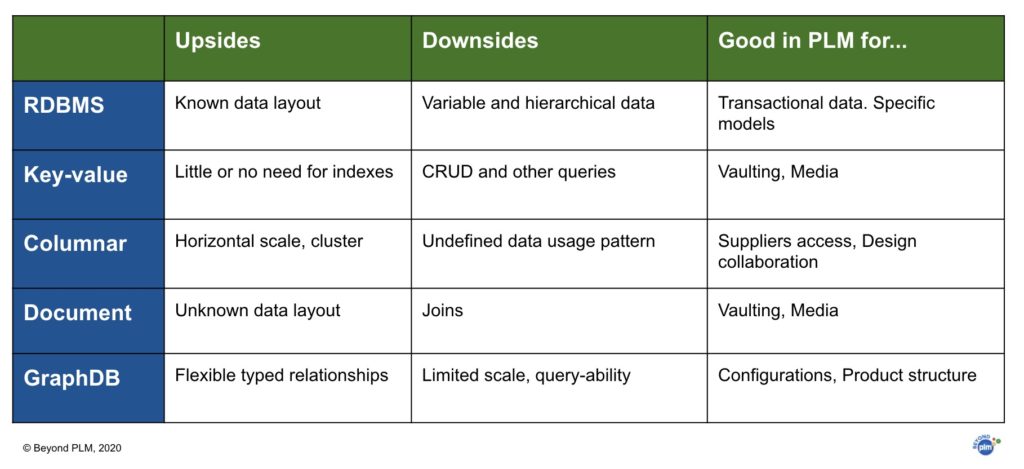
Here is my comparison of what each database is good (and not good) for is below. I’ve made it back in 2013.
My attention was caught by a few articles written by company founders in PLM space speaking about Graph Databases, linked architecture, and relationships.
Thomas Kamps of ConWeaver posted Linked Data Connectivity – Graphs are the Crux of the Biscuit. The main point of Thomas’ article is that linked structures and overlaying platforms such as ConWeaver can solve the problem of logical linking between the data and creating business solutions.
Large manufacturers are extending their products to include intelligent services based on data. Data comprise those maintained and stored in existing applications along the lifecycles as well as those gained from the field. This affects not only the products, but also the machines that make the products because at the moment there exists no closed loop covering the entire lifecycle. This is in contradiction to what Product Lifecycle Management (PLM) once promised: to cover the whole product lifecycle from requirements to delivery. Unfortunately, PLM is still bound to engineering processes, essentially PDM systems around the V-model. As sensors are the building blocks for higher value services software analyzing the impact of field data on product development becomes more and more important. So, if OEMs (or other discrete manufacturers) want to sell services as a new business model, consistent and connected (logically linked) data across all functions are a strong requirement. Otherwise, such use scenarios like flashing software updates over the air or feedback loops from field data analysis will remain pie in the sky.
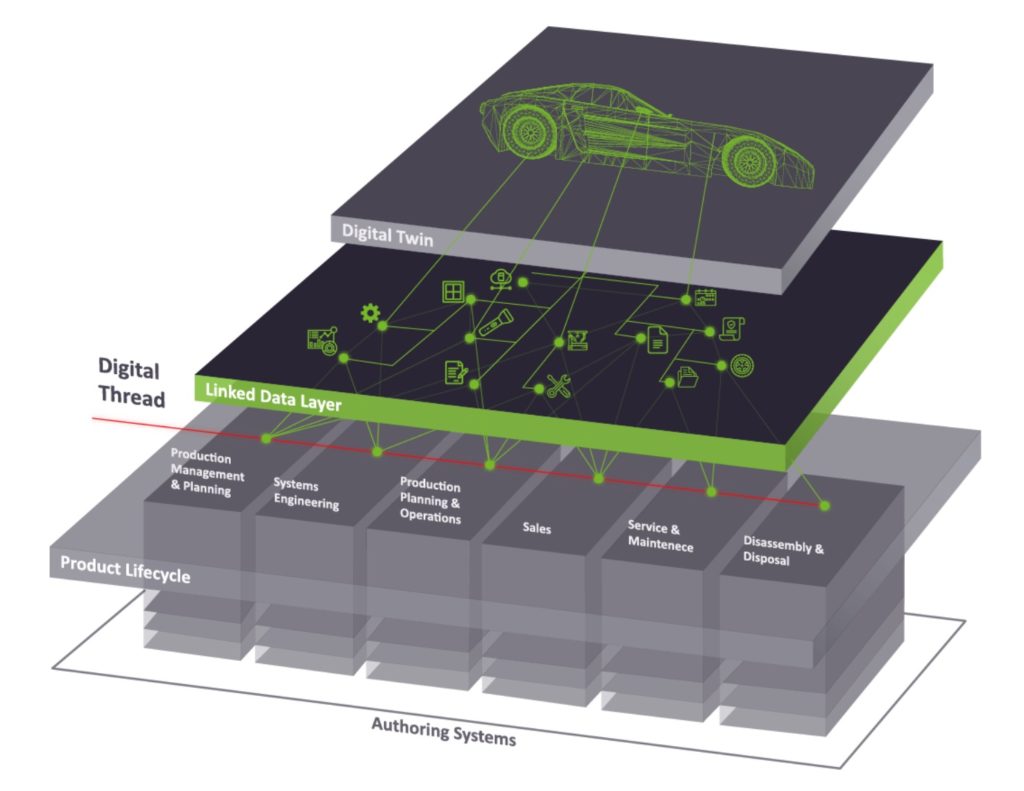
There are many good examples in Thomas’ article related to researches and graph data architectures such as Semantic Web, RDF, OWL, Knowledge Graphs, and Graph databases. The article doesn’t lead you to an immediate conclusion about right or wrong technology. However, it shows strong support to linked data and graph architecture. It is reasonable to think that ConWeaver Linksphere Low Code Big Graph Platform is an example of such architecture.
Ganister PLM is a new company that was pre-announced by Yoan Maingon and planning to provide its first production solution in June/2020. One of the differentiation is that Ganister is using Graph Database Neo4j as a data foundation. Check the last Yoann’s blog – Why a Graph Database? in which Yoann explains why Graph Database is the right platform for his new PLM system.
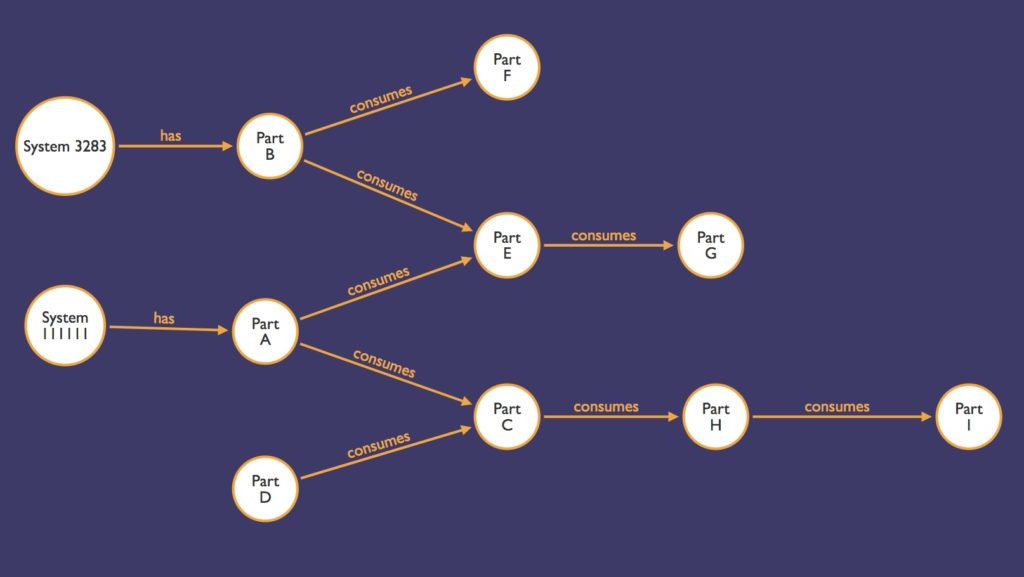
The biggest growth in PLM complexity lies in the connections between bits of information. In many complex products now, the number of potential configuration is greater than the number of parts. Which means that the relationships to resolve such structure requires a lot of relationships with critical values. We saw that growing complexity, we read all the studies about graph databases, and believed this is the right technology for PLM. While most legacy PLM solutions are relying on SQL-based systems built with tables, we challenged this status-quo and studied why Graph would beat SQL for PLM in the future.
The materials related to the comparison between RDBMS and Neo4j are mostly from Neo4j. I found the query comparison table interesting. I’ve seen it before in Neo4j marketing materials making a case for advantages of Neo4j for analytic and linked data queries.
I also want to bring my experience of building the OpenBOM SaaS PLM platform for the last few years. OpenBOM is a multi-tenant data management platform using polyglot persistence and multiple databases including Neo4j to manage links and relationships. Read my blog – Graphs, Networks, and Bill of Materials where I wrote about the role of multi-tenant data architecture and graphs in building a global graph of product structures connecting manufacturing companies and suppliers.
Back in 2018, we had a privileged to present at Boston Neo4j Graph Meetup. You can see an article about the presentation here. And here is a very simplified example of using Cypher and Neo4j data modeling tools to build queries.
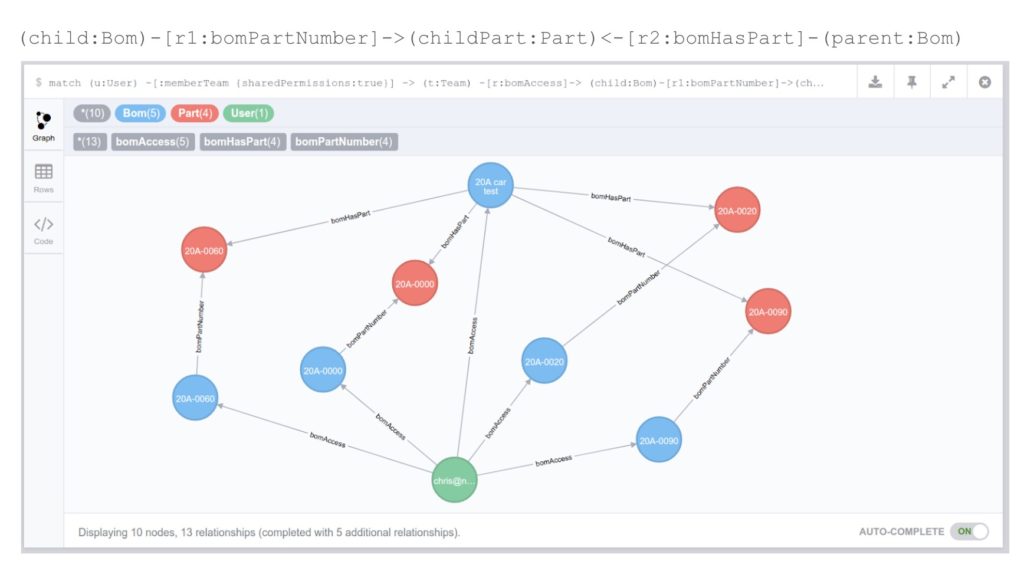
For the last five years of OpenBOM development, we gathered tons of experience managing the online SaaS platform using Neo4j as one of the elements of database management architecture. The expressiveness of graph relationships and intelligence of linked data built using Neo4j is one of the important elements of OpenBOM architecture.
What is my conclusion?
Graphs are fascinating and I mentioned it in many articles and presentations. Linked data is a very powerful concept and can go a long way in the future in building data relationships in modern manufacturing systems. As a database, Graph Database (Neo4j is one of the examples) provides a powerful mechanism to store and manage linked data. It can simplify the management of relationships, but in my view, it is in no way a solution to solve PLM data management problems. A graph database is an element in the system architecture, but it is only one part of the system. There are many others such as user experience functions and system architecture. On top of that, you apply change management strategy, business models, go to market strategy, and unit economics. All together they can provide a solution for the PLM problem, while graphs and GraphDB are just one element of an entire system. Just my thoughts…
Best, Oleg
Disclaimer: I’m co-founder and CEO of OpenBOM developing cloud based bill of materials and inventory management tool for manufacturing companies, hardware startups, and supply chain. My opinion can be unintentionally biased.

The post Will Graphs Provide A Solution For The PLM problem? appeared first on Beyond PLM (Product Lifecycle Management) Blog.
Be the first to post a comment.