

Supply chain problems are big and painful. Recently, supply chain problems became more visible than ever before with chip shortage and other examples of global economic disruption triggered by COVID 19. But these problems are not especially new and manufacturing companies live with these problems for years. So, how to fix the supply chain?
Google Cloud Platform and Supply Chain
Several of my friends shared the announcement coming from Google about Supply Chain Twin and I spent some time learning what Google announced including some partner’s announcements as well. Here is the link to Google Supply Chain Twin – check it out. The solution includes multiple elements – data segments, integrations with ERP systems (specifically SAP), and integration partners. The following passage explains what is Supply Chain Twin.
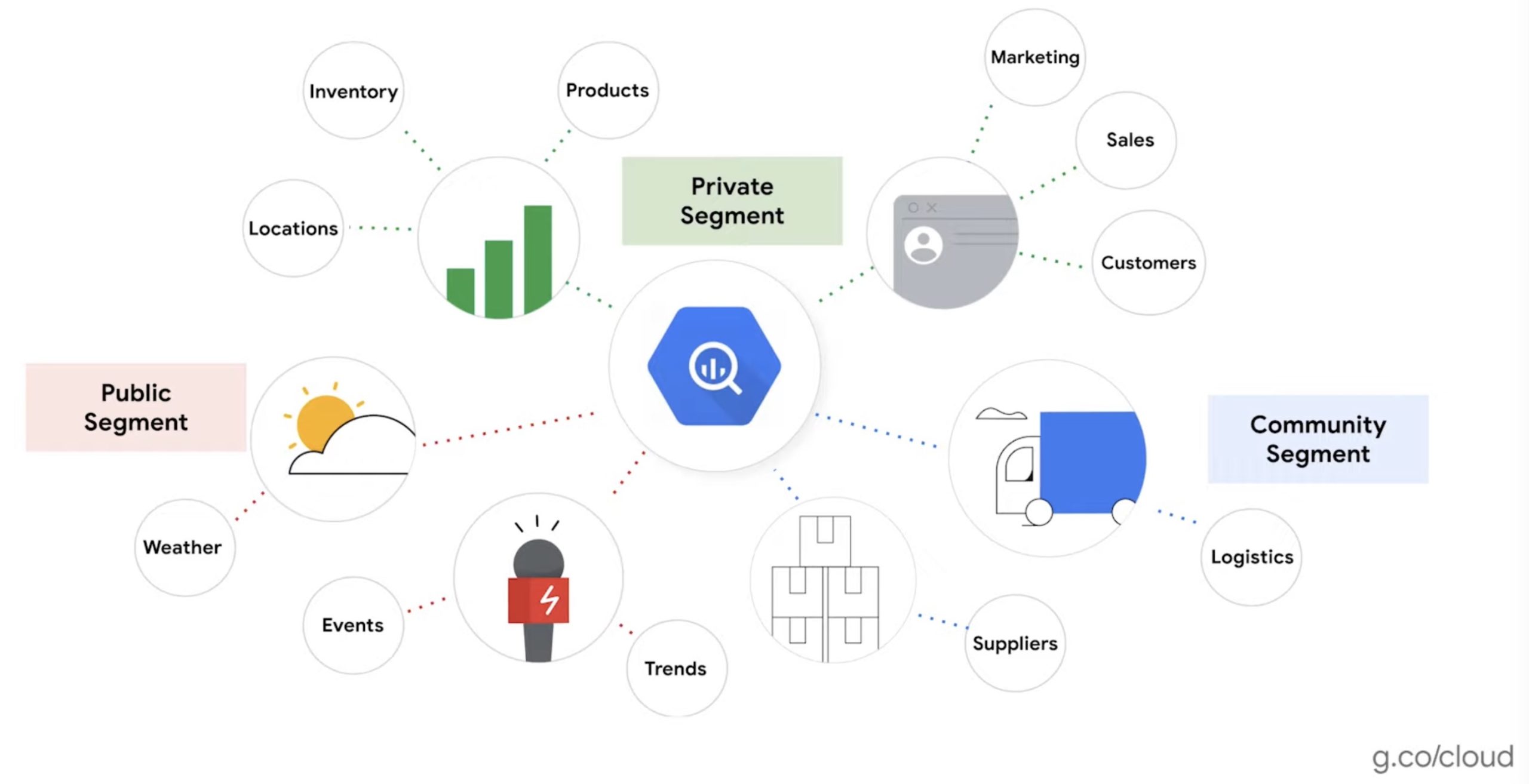
This solution provides ready-to-deploy connectors and transformation pipelines based on Cloud Data Fusion to bring data from ERP systems like SAP into the BigQuery data platform. It uses Google Cloud public datasets and the Analytics Hub to enable secure access to curated datasets from multiple data providers without complex onboarding. This semantic layer spanning the private, community, and public data segments enables data to be leveraged directly and scalably for a variety of uses, including data science.
Here is the video with a preview and explanation from Google.

However, the key elements of the solution are explained in the following passage:
The solution brings together three segments of data to enable users to holistically model the supply chain. The private segment includes data from an organization’s enterprise business systems on their business and operations, such as locations, products, orders, and inventory. The community segment includes data from supplier and partner systems such as stock and inventory levels, and partners, such as material transportation status. The public segment includes contextual data from public sources like weather, risk, or sustainability, including public datasets from Google.
The passage made me think about the strong aspects of Google Twin, but also about weaknesses and future opportunities it brings to PLM platforms. In a nutshell, it can be explained in a single phrase – intelligence is as good as the data that you bring to the system handling data and semantic layer. It is obvious that every supply chain problem starts from the ERP system and a variety of public data sets as explained in the Google announcement. So, getting your SAP data dumped to Google cloud, combine it together with public data collected by Google and you’re eventually done? Not so fast…
Product Data and Supply Chain Twin
This is an interesting place because it can identify some shallow places in the supply chain twin intelligent – lack of deep dive in manufacturing product data. This is a place where real intelligence is just going to start. How can two companies become smarter in the way they manufacture products? The core intelligence of every manufacturing company lays down deep in the understanding of data about the product, dependencies between suppliers, and early visibility on potential problems already during the design or planning phases. By making it possible, the solution can move from “reactive Supply Chain Twin” to “Predictive Supply Chain Twin”. But to get this done, more information and complex relationships can be uploaded to the global Supply Chain Twin system.
The data about the product, components, and suppliers relationships lies deep in the design information, bill of materials, and multi-disciplinary data sets representing an entire product structure including chips, components, and software elements. This is how an absence of color pigment can stop manufacturers from producing a specific car color globally. This is how a shortage of chips can shut down vehicle manufacturers in multiple factories. Getting this data is hard, it is down in old 25 years old PLM systems and CAD files. This is an opportunity for modern SaaS PLM systems available as a service online and capable to bring real product information and mix this information from other data sources. Manufacturing companies that will do it can get real competitive advantages not only to optimize supply chain flow, but make predictions about future problems already during design, product, and manufacturing planning by identifying the right suppliers and de-risking future supply chain problems.
What is my conclusion?
A supply chain is a big problem and to solve it is only possible by establishing deep data coordination between multiple data sources – suppliers, public events, weather conditions, demand, and many others. By adding product data, design, and suppliers dependencies into this equation can help to build a predictive supply chain twin to eliminate future supply chain disruption. Just my thoughts…
Best, Oleg
Disclaimer: I’m co-founder and CEO of OpenBOM developing a digital network-based platform that manages product data and connects manufacturers, construction companies, and their supply chain networks. My opinion can be unintentionally biased.

The post Google, Product Data and Predictive Supply Chain Twin appeared first on Beyond PLM (Product Lifecycle Management) Blog.
Be the first to post a comment.